

Entenda como ler tabelas de preço de LLMs antes de comparar OpenAI, Claude, Google Gemini, Kimi e outros modelos
Comparar custos de API de IA parece simples até você abrir a primeira tabela de preços.
A maioria das empresas apresenta valores por 1 milhão de tokens. À primeira vista, isso dá a impressão de que basta olhar o menor número e escolher o modelo mais barato. Mas essa leitura quase sempre leva a uma conclusão incompleta.
O motivo é simples: nem todo token custa igual.
Em uma API de inteligência artificial, existem diferentes tipos de cobrança dentro da mesma chamada. Alguns tokens representam o que você envia para o modelo. Outros representam o que o modelo gera como resposta. Outros podem ser reaproveitados por cache. Em alguns provedores, também existe custo para gravar esse cache ou mantê-lo armazenado por determinado tempo.
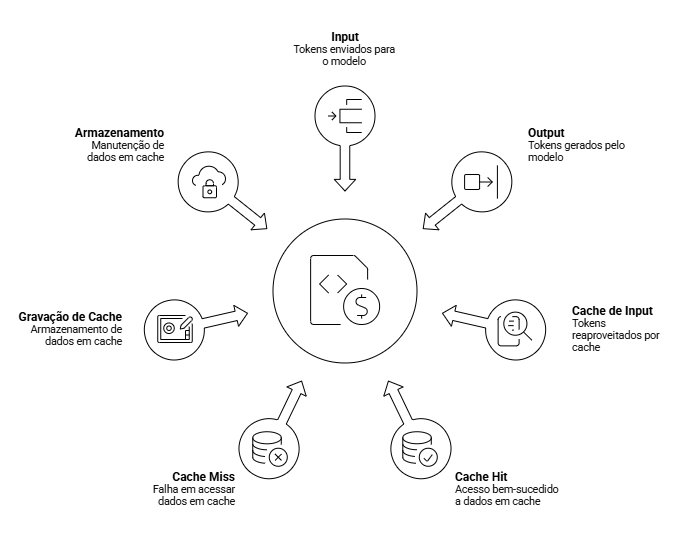
Por isso, antes de perguntar qual LLM é mais barata, a pergunta certa é outra: o que exatamente está sendo cobrado?
Essa diferença é essencial para times de produto, tecnologia, marketing, operações e dados. O custo de uma aplicação com IA não depende apenas do preço por token. Ele depende do comportamento real do produto: quanto a IA lê, quanto ela escreve, quanto contexto se repete e quanto pode ser reaproveitado.
Uma aplicação que classifica tickets de suporte tem uma dinâmica de custo. Um gerador de relatórios tem outra. Um agente com base de conhecimento fixa tem outra. Um chatbot que mantém contexto durante uma sessão tem outra.
Este guia explica como interpretar os principais componentes de uma tabela de preço de API de IA: input, output, cached input, cache hit, cache miss, cache write e storage.
Ao final, você terá uma forma mais clara de comparar provedores como OpenAI, Anthropic Claude, Google Gemini, Moonshot Kimi e outros modelos de linguagem.
O que são custos de API de IA?
Custos de API de IA são os valores cobrados pelo uso de modelos de inteligência artificial via API. Na maioria dos casos, essa cobrança é baseada em tokens.
Tokens são unidades de texto processadas pelo modelo. Eles podem representar palavras inteiras, partes de palavras, sinais de pontuação, números ou trechos de código. Quando você envia uma mensagem para uma LLM, o conteúdo é dividido em tokens. Quando o modelo responde, a resposta também é gerada em tokens.
A cobrança normalmente considera dois movimentos principais.
O primeiro é o que entra no modelo. O segundo é o que sai do modelo. O que entra costuma ser chamado de input. O que sai costuma ser chamado de output.
Mas as tabelas modernas de preço adicionaram uma camada importante: o cache.
O cache permite reaproveitar trechos de contexto já processados antes. Isso pode reduzir custo e latência em aplicações que usam prompts longos, bases de conhecimento repetidas, instruções fixas ou sessões com muitas interações.
É por isso que as tabelas de preço deixaram de mostrar apenas input e output. Hoje, é comum encontrar termos como cached input, cache hit, cache miss, cache write, context caching e storage price.
A boa notícia é que, apesar dos nomes diferentes, a lógica por trás dessas cobranças é compreensível.
Se você quer ir além de interpretar tabelas de preço e aprender a construir produtos de IA de ponta a ponta, usando Machine Learning, Deep Learning e LLMs na prática, a PM3 abriu pré-venda da nova formação AI Product Builder.
Feita para PMs que querem entregar impacto real com IA.
Clique aqui e compre seu curso com 50%OFF ->
O que são tokens em uma API de IA?
Tokens são as unidades usadas pelos modelos de IA para processar e gerar texto.
Quando você escreve uma frase, o modelo não lê exatamente como uma pessoa lê. Ele transforma o texto em pequenas partes chamadas tokens. Essas partes são usadas para calcular o custo da chamada.
Por exemplo, uma pergunta curta usa poucos tokens. Um documento longo usa muitos tokens. Uma resposta curta usa poucos tokens. Um relatório completo usa muitos tokens.
Isso significa que o custo de uma API de IA cresce conforme o volume de texto processado e gerado.
Mas existe uma nuance importante: tokens de entrada e tokens de saída geralmente têm preços diferentes.
Em muitos modelos, o output custa mais do que o input. Isso acontece porque gerar uma resposta token por token é uma parte relevante do processamento do modelo.
Por isso, uma aplicação que envia pouco texto, mas recebe respostas longas, pode custar mais do que parece. Da mesma forma, uma aplicação que envia muito texto e recebe respostas curtas pode ser mais sensível ao preço do input.
A interpretação correta começa por separar essas duas partes.
O que é input em uma API de IA?
Input é tudo que você envia para o modelo processar.
Isso inclui a pergunta do usuário, as instruções do sistema, o histórico da conversa, documentos anexados, exemplos, regras de negócio, dados recuperados de uma base, trechos de código ou qualquer outro conteúdo usado para orientar a resposta.
Em termos simples, input é o que a IA lê.
Se você envia um contrato para a IA resumir, o contrato entra como input. Se você envia uma transcrição para extrair insights, a transcrição entra como input. Se você cria um agente de atendimento com regras de tom de voz, política comercial, exemplos de resposta e base de conhecimento, tudo isso também entra como input.
Esse ponto é importante porque muitas aplicações parecem simples na interface, mas carregam um volume grande de contexto nos bastidores.
Um usuário pode digitar apenas: “resuma este documento”.
Mas, na chamada para a API, o produto pode estar enviando o documento completo, instruções de formatação, critérios de análise, exemplos de saída e regras internas da empresa.
Tudo isso entra na conta.
Por isso, aplicações que analisam muitos documentos, classificam grandes volumes de dados ou usam bases extensas tendem a ser muito sensíveis ao preço do input.
O que é output em uma API de IA?
Output é tudo que o modelo gera como resposta.
Pode ser um resumo, uma análise, uma copy, um código, uma resposta de atendimento, uma proposta comercial, um diagnóstico, um relatório ou um artigo completo.
Em termos simples, output é o que a IA escreve.
Essa parte costuma ser subestimada por quem está começando a comparar APIs de IA. Muita gente olha para o preço do input e esquece que a resposta também é cobrada.
Em muitos modelos, o output custa mais do que o input. Isso significa que aplicações que fazem a IA escrever bastante podem ficar caras mesmo quando o prompt inicial é pequeno.
Pense em dois cenários.
No primeiro, uma empresa usa IA para classificar tickets de suporte. Ela envia mensagens de clientes e recebe respostas curtas, como “financeiro”, “técnico”, “cancelamento” ou “reclamação”. Nesse caso, a IA lê muito e escreve pouco.
No segundo, uma empresa usa IA para gerar relatórios estratégicos. Ela envia um briefing curto e espera uma análise longa, estruturada e argumentativa. Nesse caso, a IA pode escrever muito mais do que lê.
Os dois produtos usam IA. Mas o perfil de custo é completamente diferente.
Por isso, não existe uma boa comparação olhando apenas para “preço por 1 milhão de tokens”. Você precisa entender se o seu produto consome mais input, mais output ou uma combinação dos dois.
O que é cache em uma API de IA?
Cache é o reaproveitamento de um contexto que já foi processado antes.
Imagine que você tem um assistente interno que sempre recebe a mesma política comercial, a mesma base de conhecimento, o mesmo guia de tom de voz e as mesmas regras de atendimento.
Sem cache, esse contexto pode ser processado novamente a cada chamada.
Com cache, parte desse conteúdo pode ser reaproveitada.
A lógica é parecida com entregar um documento grande para alguém. Na primeira vez, a pessoa precisa ler tudo. Depois, se ela já conhece aquele documento, pode responder novas perguntas sem reler tudo do zero.
Em APIs de IA, o cache pode reduzir custo e latência, principalmente em aplicações que repetem muito contexto.
Isso é comum em agentes, chatbots, copilotos internos, fluxos de atendimento, automações com prompts longos e produtos que usam bases de conhecimento recorrentes.
Mas cada empresa mostra o cache de um jeito diferente. É aqui que as tabelas de preço começam a parecer mais complicadas.
O que é cached input?
Cached input é a parte do input que já foi processada antes e pode ser reaproveitada.
Esse termo aparece de forma clara em provedores como a OpenAI.
Em vez de cobrar todo o input como se fosse novo, a tabela separa o input normal do input cacheado.
A lógica é simples:
| Termo | Significado |
|---|---|
| Input | Tokens enviados e processados normalmente |
| Cached input | Tokens de entrada reaproveitados do cache |
| Output | Tokens gerados na resposta |
Essa separação ajuda a entender por que duas chamadas com volume parecido podem ter custos diferentes.
Se uma aplicação envia sempre prompts novos, haverá pouco reaproveitamento. Se ela repete instruções, documentos ou bases de conhecimento, parte do input pode ser cacheada.
Para times de produto, isso muda a arquitetura da solução.
Um agente com instruções fixas e contexto recorrente pode ser desenhado para aproveitar melhor o cache. Uma aplicação que analisa documentos sempre diferentes terá menos benefício nessa camada.
O que é cache hit?
Cache hit acontece quando o conteúdo enviado encontra correspondência no cache e pode ser reaproveitado.
Em termos simples, é quando a IA consegue usar algo que já havia sido processado antes.
Algumas empresas usam explicitamente esse termo. A Moonshot, por exemplo, mostra no Kimi uma separação entre Input Price Cache Hit e Input Price Cache Miss.
A leitura é direta:
| Termo | O que significa |
|---|---|
| Cache hit | Input reaproveitado do cache |
| Cache miss | Input novo, processado do zero |
| Output | Tokens gerados na resposta |
Essa nomenclatura é útil porque mostra que existem dois tipos de input: o input novo e o input reaproveitado.
Os dois são conteúdos enviados ao modelo, mas não necessariamente têm o mesmo custo.
O que é cache miss?
Cache miss acontece quando o conteúdo enviado ainda não está disponível no cache.
Nesse caso, o modelo precisa processar o input como algo novo.
Em uma aplicação real, isso pode acontecer quando o usuário envia um documento inédito, quando o prompt muda muito de uma chamada para outra ou quando o contexto anterior não está mais disponível para reaproveitamento.
O cache miss costuma ser mais caro do que o cache hit porque o modelo precisa processar aquele conteúdo do zero.
Essa diferença é importante em qualquer benchmark de custo.
Se você assume que tudo será cacheado, pode subestimar o custo. Se assume que nada será cacheado, pode superestimar o custo em aplicações com muito contexto repetido.
A análise correta está no meio: entender quanto do seu uso real tende a ser novo e quanto tende a ser reaproveitado.
Se você quer ir além de interpretar tabelas de preço e aprender a construir produtos de IA de ponta a ponta, usando Machine Learning, Deep Learning e LLMs na prática, a PM3 abriu pré-venda da nova formação AI Product Builder.
Feita para PMs que querem entregar impacto real com IA.
Clique aqui e compre seu curso com 50%OFF ->
O que é cache write?
Cache write é o custo de gravar um conteúdo no cache para reaproveitamento futuro.
Esse termo aparece de forma mais explícita em provedores como a Anthropic, nos modelos Claude.
Nesse tipo de tabela, o cache pode ser separado em etapas:
| Termo | O que significa |
|---|---|
| Base Input Tokens | Input normal, processado sem cache |
| 5m Cache Writes | Custo para gravar conteúdo no cache por 5 minutos |
| 1h Cache Writes | Custo para gravar conteúdo no cache por 1 hora |
| Cache Hits & Refreshes | Custo para reutilizar ou renovar algo já cacheado |
| Output Tokens | Tokens gerados na resposta |
Aqui, a diferença é que o cache não aparece apenas como “input cacheado”. Ele aparece como uma operação com duas fases.
Primeiro, você grava o conteúdo no cache. Depois, reutiliza esse conteúdo em chamadas futuras.
A duração também importa. Um cache de 5 minutos pode ser útil para sessões curtas e fluxos em sequência. Um cache de 1 hora pode fazer sentido quando o mesmo contexto precisa ser reaproveitado por mais tempo.
Esse modelo de cobrança é especialmente relevante para agentes, copilotos, assistentes internos e produtos com múltiplas interações dentro da mesma sessão.
O que é storage price?
Storage price é o custo para manter um conteúdo armazenado no cache por determinado período.
Esse tipo de cobrança aparece em estruturas como a do Google Gemini, onde o cache pode envolver não apenas o reaproveitamento de tokens, mas também o custo de armazenamento do contexto.
A tabela pode trazer termos como:
| Termo | O que significa |
|---|---|
| Input price | Tokens enviados para o modelo |
| Output price | Tokens gerados na resposta |
| Context caching price | Tokens reaproveitados do cache |
| Storage price | Custo para manter o cache armazenado por hora |
Essa camada muda a análise.
O cache pode reduzir o custo de processamento do input, mas manter o conteúdo salvo também pode gerar custo. Por isso, a economia depende da frequência de reutilização.
Se o conteúdo é armazenado e reaproveitado muitas vezes, o cache pode compensar. Se o conteúdo fica armazenado e quase não é usado, o storage pode reduzir ou eliminar a vantagem.
Para produto, a pergunta passa a ser: esse contexto será reutilizado o suficiente para justificar o armazenamento?
Como OpenAI, Claude, Google Gemini e Kimi mostram os custos
Cada empresa usa nomes próprios, mas a lógica central costuma ser parecida.
A OpenAI organiza a leitura em três blocos principais: input, cached input e output.
| OpenAI | Significado |
|---|---|
| Input | Tokens enviados e processados normalmente |
| Cached input | Tokens reaproveitados do cache |
| Output | Tokens gerados na resposta |
A Anthropic, com Claude, detalha mais a mecânica do cache.
| Claude | Significado |
|---|---|
| Base Input Tokens | Input normal |
| 5m Cache Writes | Gravação no cache por 5 minutos |
| 1h Cache Writes | Gravação no cache por 1 hora |
| Cache Hits & Refreshes | Reutilização ou renovação do cache |
| Output Tokens | Resposta gerada |
O Google Gemini adiciona uma camada de armazenamento.
| Google Gemini | Significado |
|---|---|
| Input price | Tokens enviados para o modelo |
| Output price | Tokens gerados na resposta |
| Context caching price | Tokens reaproveitados do cache |
| Storage price | Custo para manter o cache salvo por hora |
A Moonshot, com Kimi, mostra a diferença entre cache hit, cache miss e output.
| Moonshot Kimi | Significado |
|---|---|
| Input Price Cache Miss | Input novo, processado do zero |
| Input Price Cache Hit | Input reaproveitado do cache |
| Output Price | Tokens gerados na resposta |
A conclusão é que os nomes mudam, mas a pergunta principal continua a mesma: quanto custa fazer a IA ler, reaproveitar contexto e escrever uma resposta?
Como calcular o custo real de uma API de IA
A forma mais útil de calcular o custo real de uma API de IA é separar os componentes da chamada.
Uma fórmula conceitual seria:
Custo total = input normal + input cacheado + output + cache write + storage
Nem toda API cobra todos esses itens. Algumas simplificam a cobrança. Outras detalham mais. Mas essa fórmula ajuda a organizar o raciocínio.
Na prática, você pode pensar assim:
| Componente | Pergunta que você deve fazer |
|---|---|
| Input normal | Quanto texto novo estou enviando? |
| Input cacheado | Quanto contexto repetido posso reaproveitar? |
| Output | Quanto texto a IA vai gerar? |
| Cache write | Preciso pagar para gravar o contexto no cache? |
| Storage | Existe custo para manter esse cache ativo? |
Imagine uma aplicação que envia 10 mil tokens e recebe 2 mil tokens de resposta.
Sem cache, a conta conceitual seria:
| Parte da chamada | Tipo de custo |
|---|---|
| 10 mil tokens enviados | Input normal |
| 2 mil tokens gerados | Output |
Agora imagine que, desses 10 mil tokens enviados, 6 mil são instruções fixas já reaproveitadas de chamadas anteriores.
A composição muda:
| Parte da chamada | Tipo de custo |
|---|---|
| 4 mil tokens novos | Input normal |
| 6 mil tokens repetidos | Cached input ou cache hit |
| 2 mil tokens gerados | Output |
Para o usuário final, a experiência pode parecer idêntica. Ele fez uma pergunta e recebeu uma resposta.
Para a fatura da API, a diferença pode ser significativa.
É por isso que o desenho do produto influencia diretamente o custo.
Como comparar preços de LLMs do jeito certo
O erro comum é abrir duas tabelas de preço e comparar apenas o valor de input.
Essa comparação pode ser útil em uma estimativa inicial, mas raramente basta para uma decisão de produto.
Um modelo pode ter input barato e output caro. Outro pode ter cache vantajoso, mas storage relevante. Outro pode parecer caro no input normal, mas compensar em fluxos com muito cache. Outro pode ser excelente para respostas curtas e caro para geração longa.
O benchmark correto precisa simular o uso real.
Para isso, comece pelo tipo de aplicação.
| Tipo de uso | O que mais pesa |
|---|---|
| Classificação em massa | Input |
| Extração de dados | Input |
| Geração de artigos e relatórios | Output |
| Atendimento com respostas longas | Output |
| Agentes com contexto fixo | Cache |
| Chatbots com base de conhecimento | Cache |
| Aplicações com cache persistente | Storage + cache hit |
| Uso geral | Input + output |
Se a IA lê muito e responde pouco, olhe mais para input.
Se a IA escreve muito, olhe mais para output.
Se a IA repete muito contexto, olhe mais para cache.
Se o provedor cobra armazenamento de cache, olhe também para storage.
Essa leitura evita decisões ruins. A pergunta certa não é “qual modelo tem o menor preço por 1 milhão de tokens?”. A pergunta certa é “qual modelo entrega minha tarefa real pelo melhor custo total?”.
Exemplos práticos de interpretação
Um sistema de triagem de leads provavelmente envia muitos dados e espera respostas curtas. Nesse caso, input pesa mais. O modelo precisa ler nome, cargo, empresa, segmento, histórico e critérios de qualificação. A resposta pode ser apenas uma nota ou categoria.
Um gerador de relatórios executivos pode enviar um briefing pequeno e receber uma análise longa. Nesse caso, output pesa mais. O custo principal pode estar na resposta gerada.
Um agente de suporte com base de conhecimento fixa pode se beneficiar muito do cache. As instruções, políticas e documentos se repetem em várias conversas. Se esse contexto puder ser reaproveitado, o custo por interação pode cair.
Um copiloto interno que mantém documentos cacheados por longos períodos precisa avaliar storage. Se os documentos são reutilizados com frequência, o armazenamento pode compensar. Se ficam parados, talvez não.
Um fluxo no n8n que processa milhares de linhas de uma planilha deve olhar com cuidado para input e output. Se cada linha gera uma resposta curta, o input domina. Se cada linha gera uma análise detalhada, o output começa a pesar.
Esses exemplos mostram que o preço de uma LLM depende menos da tabela isolada e mais do comportamento da aplicação.
Erros comuns ao interpretar custos de API de IA
O primeiro erro é achar que todos os tokens custam igual.
Eles não custam. Input, output, cached input, cache hit, cache miss, cache write e storage podem ter preços diferentes.
O segundo erro é olhar apenas para o input.
Isso distorce a análise quando a aplicação gera respostas longas. Em muitos casos, o output é a parte mais cara da operação.
O terceiro erro é ignorar cache.
Em agentes e chatbots com contexto repetido, o cache pode mudar bastante o custo final.
O quarto erro é assumir cache demais.
Nem todo conteúdo será reaproveitado. Prompts muito variáveis, documentos sempre novos e contextos que mudam a cada chamada podem gerar muitos cache misses.
O quinto erro é esquecer storage.
Quando o provedor cobra para manter cache armazenado, a economia depende da reutilização. Cache parado também pode custar.
O sexto erro é comparar modelos sem simular o uso real.
Uma tabela de preço mostra possibilidades. O produto real mostra a conta.
Como reduzir custos com API de IA
A primeira forma de reduzir custos é diminuir input desnecessário.
Muitas aplicações enviam contexto demais para o modelo. Instruções repetidas, históricos longos, documentos completos e dados irrelevantes podem aumentar a fatura sem melhorar a resposta.
A segunda forma é controlar o tamanho do output.
Se a aplicação precisa apenas de uma classificação, não faz sentido pedir uma explicação longa. Se o produto precisa de um resumo curto, limite a resposta. Quanto mais o modelo escreve, mais tokens de output são gerados.
A terceira forma é desenhar melhor o uso de cache.
Prompts fixos, bases recorrentes e instruções longas podem ser estruturados para aproveitar cache quando o provedor oferece essa possibilidade.
A quarta forma é escolher o modelo conforme a tarefa.
Nem toda tarefa precisa do modelo mais caro. Classificação simples, extração de campos e reformulações curtas podem funcionar bem com modelos mais econômicos. Tarefas complexas, com raciocínio mais profundo ou maior exigência de qualidade, podem justificar modelos mais caros.
A quinta forma é medir uso real.
Sem monitoramento, a equipe fica no escuro. O ideal é acompanhar tokens de input, output, cache hit, cache miss, custo por tarefa e custo por usuário.
A métrica mais útil não é apenas custo por token. É custo por tarefa concluída com qualidade.
Como estruturar uma estratégia de custos para produtos com IA
Para times de produto, a gestão de custos de IA precisa entrar desde o desenho da funcionalidade.
Antes de colocar um recurso em produção, vale responder algumas perguntas.
Quanto contexto será enviado por chamada? Qual será o tamanho médio da resposta? Existe contexto fixo? O histórico da conversa precisa ser enviado inteiro? Dá para resumir partes antigas? O provedor oferece cache? O cache tem custo de escrita ou armazenamento? O usuário realmente precisa de uma resposta longa? Qual modelo entrega qualidade suficiente para essa tarefa?
Essas perguntas ajudam a evitar surpresas.
Um produto com IA pode parecer barato no protótipo e caro em escala. No protótipo, poucas pessoas usam, poucos documentos são enviados e as chamadas são controladas. Em escala, o volume cresce, os casos de uso variam e a fatura passa a refletir o comportamento real dos usuários.
Por isso, custo de IA é uma decisão de produto, não apenas de engenharia.
Ele afeta margem, precificação, pacote comercial, limites de uso, experiência do usuário e arquitetura.
Perguntas frequentes sobre custos de API de IA
O que é input em uma API de IA?
Input é tudo que você envia para o modelo processar. Pode ser uma pergunta, um prompt, um documento, uma transcrição, um histórico de conversa, uma base de conhecimento ou uma instrução do sistema.
Em termos simples, input é o que a IA lê antes de responder.
O que é output em uma API de IA?
Output é tudo que o modelo gera como resposta. Pode ser um resumo, uma análise, uma copy, um código, um relatório, uma classificação ou uma resposta de atendimento.
Em termos simples, output é o que a IA escreve.
O que é cached input?
Cached input é a parte do input que já foi processada antes e pode ser reaproveitada.
Isso costuma acontecer quando uma aplicação usa prompts fixos, bases de conhecimento repetidas, instruções longas ou documentos recorrentes.
O que é cache hit?
Cache hit acontece quando o sistema encontra no cache um conteúdo que já havia sido processado antes.
Ou seja, a IA consegue reaproveitar parte do contexto.
O que é cache miss?
Cache miss acontece quando o conteúdo enviado ainda não está disponível no cache.
Nesse caso, o modelo precisa processar aquele input do zero.
O que é cache write?
Cache write é o custo de gravar um conteúdo no cache para reaproveitamento futuro.
Esse termo aparece de forma mais explícita em modelos que separam a cobrança entre input normal, gravação no cache, reutilização do cache e output.
O que é storage price?
Storage price é o custo para manter um conteúdo armazenado no cache por determinado período.
Essa lógica aparece em provedores que cobram não apenas pelo uso do cache, mas também pelo tempo em que o conteúdo fica salvo.
Por que o output costuma ser mais caro que o input?
Porque gerar uma resposta exige processamento durante a criação de cada novo token. Por isso, em muitos modelos, os tokens de saída têm preço maior do que os tokens de entrada.
Na prática, aplicações que geram textos longos, relatórios, artigos ou análises detalhadas precisam olhar com atenção para o custo de output.
Como comparar corretamente o preço de duas APIs de IA?
A melhor forma é simular o uso real do produto.
Você precisa estimar quanto a aplicação envia de input, quanto recebe de output, quanto contexto se repete, quanto pode ser cacheado e se existe custo de armazenamento.
Comparar apenas uma coluna da tabela, como o preço do input, pode levar a uma decisão errada.
Quando devo olhar mais para input?
Quando a aplicação lê muito e responde pouco.
Isso acontece em classificação de tickets, análise de planilhas, extração de informações, triagem de leads, leitura de documentos e processamento de grandes volumes de dados com respostas curtas.
Quando devo olhar mais para output?
Quando a aplicação gera respostas longas.
Isso acontece em criação de artigos, relatórios, propostas comerciais, análises estratégicas, roteiros, respostas completas de atendimento e copilotos de escrita.
Quando o cache é mais importante?
O cache é mais importante quando a aplicação repete muito contexto.
Isso acontece em agentes com instruções fixas, chatbots com base de conhecimento, assistentes internos, fluxos de atendimento, automações com prompts longos e produtos que reutilizam os mesmos documentos ou regras de negócio.
Qual é o maior erro ao interpretar preço de API de IA?
O maior erro é achar que todos os tokens custam igual.
Uma chamada pode ter input normal, input cacheado, output, cache write e até storage. O custo real depende da composição dessa chamada, não apenas do preço por 1 milhão de tokens.
O que você leu neste artigo
Neste artigo, você viu que interpretar custos de API de IA exige olhar além do preço por 1 milhão de tokens.
O ponto central é entender que existem diferentes tipos de cobrança dentro de uma chamada.
Input é o que a IA lê.
Output é o que ela escreve.
Cached input é a parte da entrada reaproveitada.
Cache hit é quando o contexto é reutilizado.
Cache miss é quando o conteúdo precisa ser processado do zero.
Cache write é a gravação desse contexto no cache.
Storage é o custo de manter o cache disponível por tempo.
Também vimos que cada empresa organiza essa cobrança com nomes diferentes. OpenAI costuma mostrar input, cached input e output. Claude detalha cache writes, cache hits e duração do cache. Google Gemini adiciona o custo de armazenamento. Moonshot Kimi trabalha com cache hit, cache miss e output.
A principal conclusão é que comparar APIs de IA apenas pelo preço do input pode distorcer a análise. Um produto que lê muito tem uma dinâmica de custo. Um produto que escreve muito tem outra. Um agente que reaproveita contexto tem outra. Uma aplicação que armazena cache por mais tempo também precisa considerar esse custo.
O melhor benchmark é aquele que simula o uso real do produto.
Antes de escolher uma API de IA, entenda o comportamento da sua aplicação: quanto ela lê, quanto ela escreve, quanto ela repete e quanto ela reaproveita.
É isso que revela o custo real.
Se você quer ir além de interpretar tabelas de preço e aprender a construir produtos de IA de ponta a ponta, usando Machine Learning, Deep Learning e LLMs na prática, a PM3 abriu pré-venda da nova formação AI Product Builder.
Feita para PMs que querem entregar impacto real com IA.
Clique aqui e compre seu curso com 50%OFF ->




